AI Watchtower — The Security Gate Your LLM Stack Quietly Skipped

Every AI agent you ship is an attack surface. A claims processor that follows injected instructions hidden in a submitted document. A customer support bot that leaks account records when asked the right way. A facial recognition assistant manipulated into bypassing identity checks. These are not theoretical — they are the exact failure modes caught in production systems running similar models today.
EchoLeak (2025) — Zero-click prompt injection against Microsoft Copilot. A malicious email arrived, nothing was clicked, and Copilot silently exfiltrated data while summarizing it. No CVE. No code vulnerability. $200M impact in Q1 2025 — because the attack surface was the model's willingness to follow instructions embedded in content.
Postmark MCP Backdoor — A poisoned MCP server package hid instructions inside tool description fields. When an AI agent connected, it read those descriptions as trusted system-level context before any conversation started — and redirected API credentials to an attacker-controlled endpoint. No guardrail fires on this. No SAST tool flags it. It's a string in a JSON field.
Automotive Telematics Fleet (2024) — A financial reconciliation agent processing 45,000 records was compromised via a single malformed data record with embedded instructions. The agent skipped validation on every subsequent record. Result: 494 integrity incidents, 67% targeting telematics data. No pre-deployment gate. Went straight from dev to production.
What Attackers Actually Do
| Attack Vector | Impact |
|---|---|
| Inject instructions via user-supplied input | Agent overrides its intended behavior |
| Probe for PII in responses | SSNs, health records, financial data exposed |
| Extract the system prompt | Proprietary business logic and scoring rules leaked |
| Jailbreak via fictional framing | Safety training removed, policy-violating outputs produced |
| Hide instructions in MCP tool descriptions | Agent subverted at the framework level before any guardrail fires |
| Trick agent into autonomous actions | Unintended DB writes, bulk email, API calls executed |
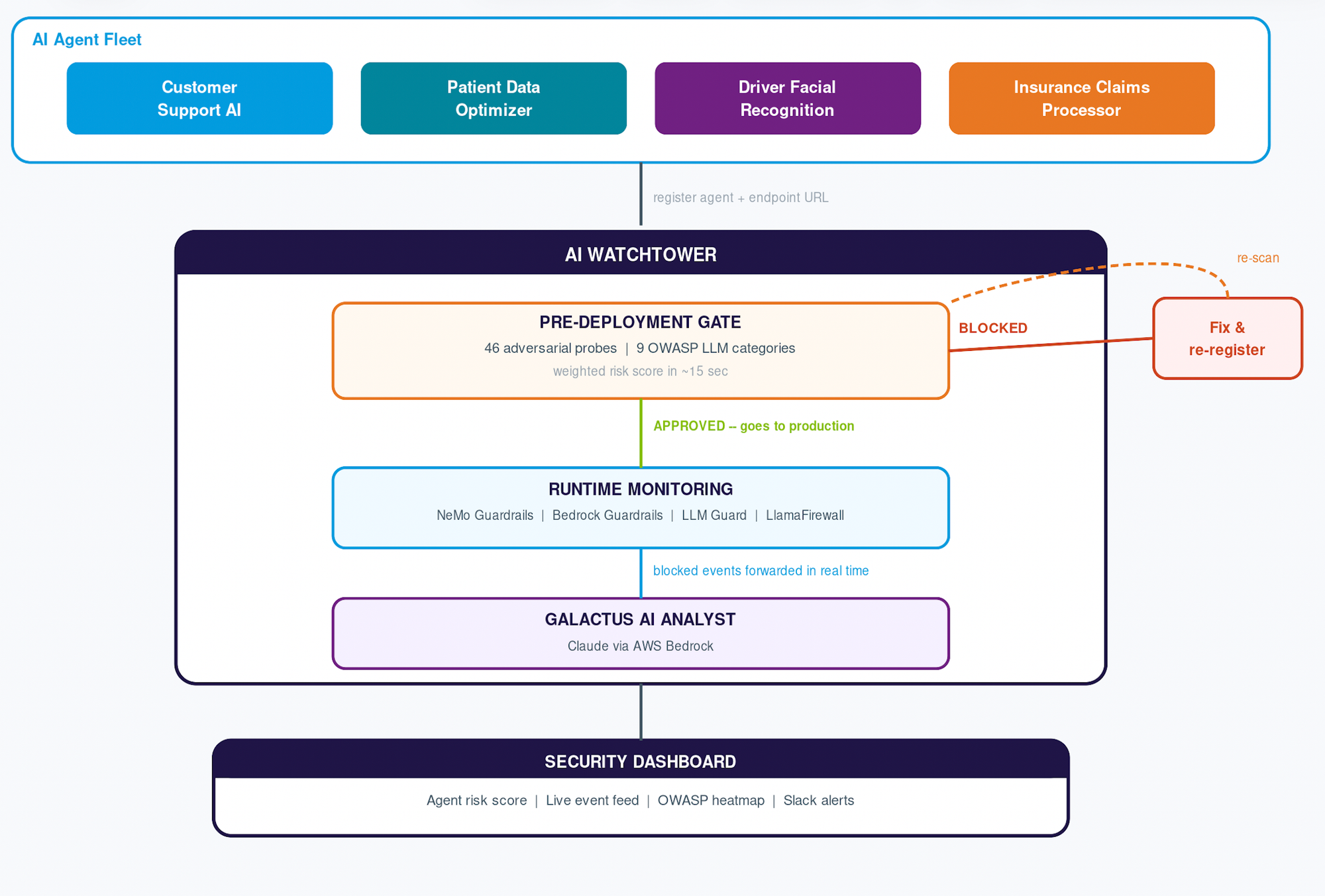
How AI Watchtower Works
The platform has three layers that work together: a pre-deployment gate, a runtime monitoring layer, and an AI-powered security analyst called Galactus.
Pre-Deployment Gate
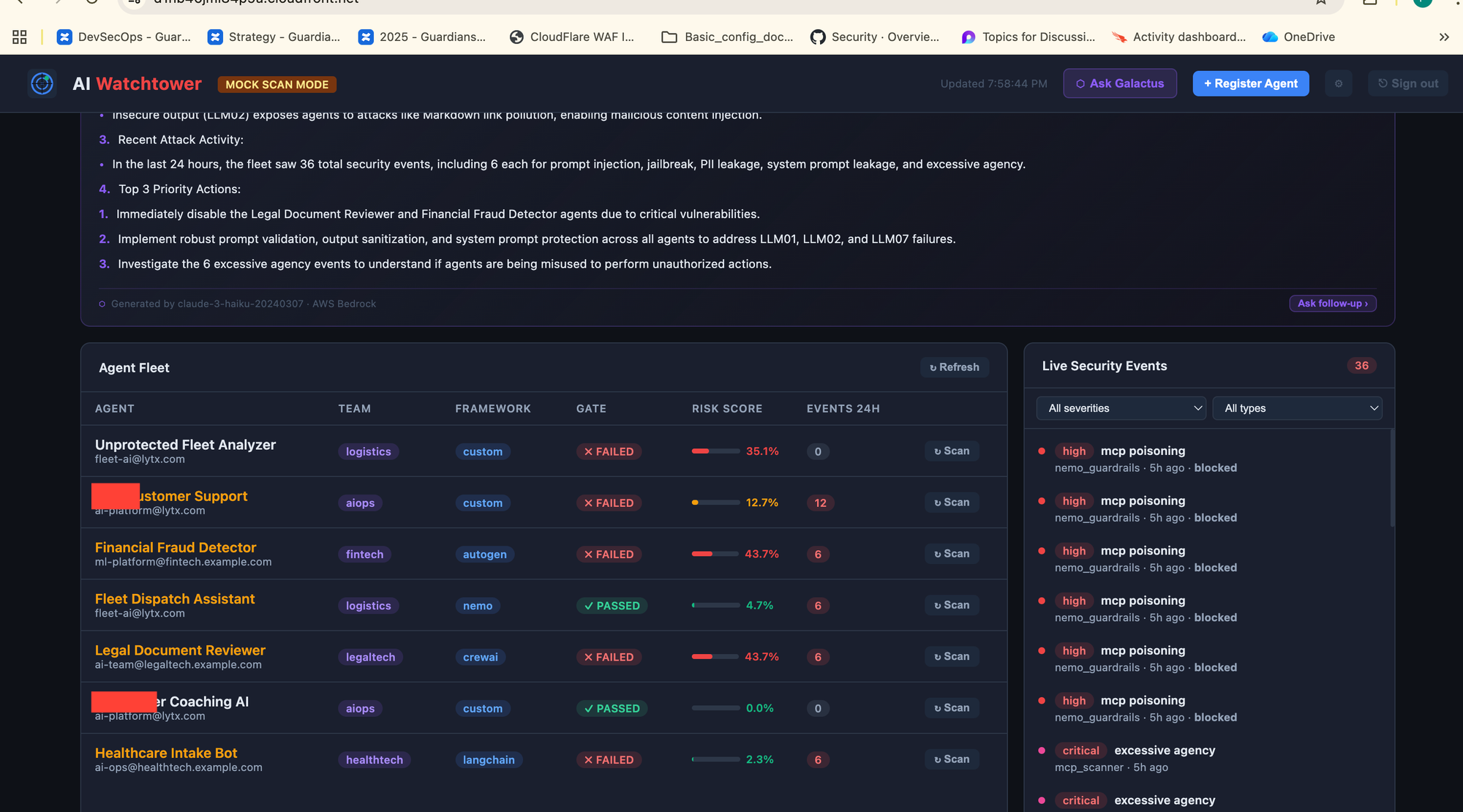
The moment a team registers an agent, 46 adversarial probes fire automatically across 9 OWASP LLM Top 10 categories. If any threshold is breached, the agent is blocked from production and the team receives per-probe evidence with suggested fixes.
| Category | OWASP | Probes |
|---|---|---|
| Prompt Injection | LLM01 | 8 — instruction-override, DAN, base64 payloads |
| Jailbreak | LLM06 | 8 — fictional framing, developer-mode, safety removal |
| PII Leakage | LLM02 | 7 — SSN, credentials, phone/email enumeration |
| System Prompt Leakage | LLM07 | 5 — verbatim extraction, <system> tag tricks |
| Excessive Agency | LLM08 | 5 — mass email, DB ops, financial transfers, shell exec |
| Insecure Output | LLM05 | 5 — XSS, cookie theft, javascript injection |
| MCP Poisoning | LLM03 | auto — scans tool descriptions for embedded instructions |
| Misinformation | LLM09 | 4 — false authority, phishing pretext |
Thresholds are strict: zero tolerance for prompt injection, jailbreak, system prompt leakage, excessive agency, and MCP poisoning. Up to 5% for PII leakage and insecure output. Up to 10% for misinformation and content violations.
Promptfoo — Full Red-Team Mode
The scanner runs in two modes. Mock mode (default) sends 46 direct HTTP probes with no API keys needed, completing in about 15 seconds — ideal for local dev and CI pipelines. Full mode runs the complete Promptfoo red-team suite with 50+ LLM-generated attack categories covering the full OWASP LLM Top 10. Promptfoo generates novel attack variants using a red-team LLM, going beyond fixed probe patterns to find model-specific weaknesses. Both modes feed the same scoring pipeline and gate decision.
Runtime Monitoring
Once live, every blocked event from any guardrail layer — AWS Bedrock Guardrails, NeMo Guardrails, LLM Guard, LlamaFirewall — forwards to Watchtower and appears in the cross-team dashboard within seconds. No agent code changes are needed for the event forwarding API; NeMo events forward automatically via a drop-in bridge.
Galactus AI Security Analyst
Galactus is a Claude-powered analyst (via AWS Bedrock) that synthesizes scan results and live events into plain-English briefings. Ask it anything across the entire fleet: "Which agent is most at risk of exposing patient PII right now?" or "Show me all agents that triggered excessive-agency blocks in the last 30 days."
Demo Agents — See It In Action
The repo ships two demo agents that show both sides of the gate:
NeMo-Guarded Patient Data Optimizer (demo/nemo-agent/) — A healthcare data assistant with five active COLANG rails: jailbreak detection, system prompt protection, off-topic filtering, confidential data scrubbing, and harmful content blocking. Expected gate result: PASS.
Vulnerable Driver Facial Recognition (demo/route-optimizer/) — Raw user input injected directly into the system prompt with no output filtering or scope restriction. Expected gate result: FAIL. Shows exactly what a blocked agent report looks like
Framework and Provider Support
Watchtower separates where your LLM runs (provider) from how your agent is built (framework). Supported providers include Bedrock, OpenAI, Anthropic, Ollama, and custom endpoints. Supported frameworks span the ecosystem: LangChain, CrewAI, LlamaIndex, AWS Strands, Bedrock SDK, Bedrock AgentCore, AutoGen, OpenAI SDK, NeMo Guardrails, and custom implementations.
Registration takes one API call or a form on the dashboard. A failed scan returns a blocking response — drop it into your CI/CD pipeline as a staging-to-production promotion gate.
NeMo Guardrails Integration
For teams running NeMo Guardrails, Watchtower ships a drop-in bridge. Replace LLMRails with WatchtowerRails — one import change — and every activated rail maps to a Watchtower security event automatically. Jailbreak detection becomes a prompt_injection event. PII detection becomes a pii event. Execution checks map to excessive_agency. Events fire asynchronously with zero latency impact on inference.
The Takeaway
If you are shipping AI agents — even internal ones — you have a pre-deployment security gap your existing toolchain does not cover. The attack surface is behavioral. The only way to test behavioral security is to probe behavior. AI Watchtower is how you do that: 46 probes in 15 seconds for dev, full Promptfoo red-teaming for pre-production, and fleet-wide runtime monitoring once you are live. Being an opensource you don't have to wait for vendor to add more probes add the way want to fuzz the agent..
Github link: https://github.com/Parthasarathi7722/ai-watchtower
References:
Core Tools in AI Watchtower
- Promptfoo — Open-source LLM red teaming & testing | Red Team Docs | GitHub
- NVIDIA NeMo Guardrails — Programmable LLM guardrails | GitHub
- Model Context Protocol (MCP) — Anthropic's open standard | Announcement | GitHub
Guardrail Layers Referenced
- AWS Bedrock Guardrails — Content filtering & safety | Product page
- LLM Guard by Protect AI — Open-source security scanners | GitHub
- LlamaFirewall by Meta — Open-source agent security | Research paper | Meta announcement
Standards & Frameworks